
华为诺亚频域LLM「帝江」:仅需1/50训练成本,7B模型媲美LLaMA,推理加速5倍
华为诺亚频域LLM「帝江」:仅需1/50训练成本,7B模型媲美LLaMA,推理加速5倍基于 Transformer 架构的大语言模型在 NLP 领域取得了令人惊艳的效果,然而,Transformer 中自注意力带来的二次复杂度使得大模型的推理成本和内存占用十分巨大,特别是在长序列的场景中。
来自主题: AI技术研报
7283 点击 2024-04-03 17:29
 搜索
搜索
基于 Transformer 架构的大语言模型在 NLP 领域取得了令人惊艳的效果,然而,Transformer 中自注意力带来的二次复杂度使得大模型的推理成本和内存占用十分巨大,特别是在长序列的场景中。
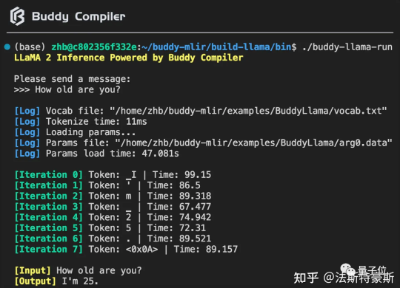
Buddy Compiler 端到端 LLaMA2-7B 推理示例已经合并到 buddy-mlir仓库[1]主线。我们在 Buddy Compiler 的前端部分实现了面向 TorchDynamo 的第三方编译器,从而结合了 MLIR 和 PyTorch 的编译生态。